
MatMul on FPGA over PCIE
TL;DR
If you want to deploy some logic to a FPGA and talk to that logic over PCIE, and you want to stream data to that logic, it’s surprisingly confusing how to wire everything together. It can be done using Xilinx’s DMA/Bridge Subsystem for PCI Express. Here’s what it looks like when it’s all done:
One thing that made figuring this out challenging is that while there’s an abundance of guides that employ the Zynq platform (including the adjacent ARM core functioning as the processor system), there are almost none that discuss accomplishing the goal using other boards/chips/configurations.
Disclaimer
Since so much of the tooling around FPGAs is proprietary (and thus brittle as hell) it’s worth mentioning that I got this to work using 2021.1 Xilinx tools and on an Artix 7 (PicoEVB with XC7A50T-CSG325-1). YMMV (in particular, with regards to the ports).
Acronyms
- FPGA: Field Programmable Gate Array; the device which we’re programming.
- CPU: Central Processing Unit; the processor on the host device.
- I/O: Input/Output; self-explanatory.
- PCIE: Peripheral Component Interconnect (Express); the communication interface we’re using to communicate with the host device (i.e., the CPU and operating system and memory).
- AXI: Advanced eXtensible Interface; the communication interface that the components will use to communicate amongst themselves, on the FPGA itself.
- DMA: Direct Memory Access; a system that lets individual components access memory directly, independently of the CPU.
- MMIO: Memory-Mapped I/O; uses the same address space to address both memory and I/O devices. The memory and registers of the I/O devices are mapped to (associated with) address values (in the address range assigned by the DMA controller).
- IP: Intellectual Property; wacky name for a module/chunk of logic.
- RTL: Register-Transfer Level; circuits designed in terms signals and registers.
- HLS: High-Level Synthesis; a technique for translating procedural code (e.g., C++) to RTL designs.
The Kernel
As the kernel we’ll use matrix multiplication (matmul_accel), which is simple enough for Vitis HLS to synthesize for us and simultaneously complex enough to (potentially) benefit from having data streamed to it. The implementation is based on twaclaw/matmult/hls/matmult_accel.cpp (my implementation is here) but the relevant bits are (with some slight changes for exposition):
#define N 8 // characteristic dimension of the matrix
#define N2 64 // N*N
#define DWIDTH 512 //
#define WUSER 0 // bit width of the TUSER signal
#define WID 0 // bit width of the TID signal
#define WDEST 0 // bit width of the TDEST signal
typedef ap_axiu<DWIDTH, WUSER, WID, WDEST> axis_t;
...
void matmult_accel(hls::stream<axis_t> &in, hls::stream<axis_t> &out) {
// #pragma HLS INTERFACE s_axilite port = return bundle = control
#pragma HLS INTERFACE axis port = in
#pragma HLS INTERFACE axis port = out
...
kernel_mmult<DataType>(l_A, l_B, l_C);
...
return;
}
Note that in some places you see ap_axiu<DATA_WIDTH, 0, 0, 0>; i.e., with WUSER, WID, and WDEST are set to 0, the generated RTL will not include the TUSER, TID, and TDEST signals in the interface.
One crucial thing that took quite a while to hit upon was
// #pragma HLS INTERFACE s_axilite port = return bundle = control
which prevents an AXI4-Lite control bus from being synthesized (in the AXI wrapper around the kernel IP) and instead produces a module with a ap_ctrl bundle. In principle such a control bus shouldn’t be an issue; it corresponds to a set of registers that seem straightforward enough to manipulate
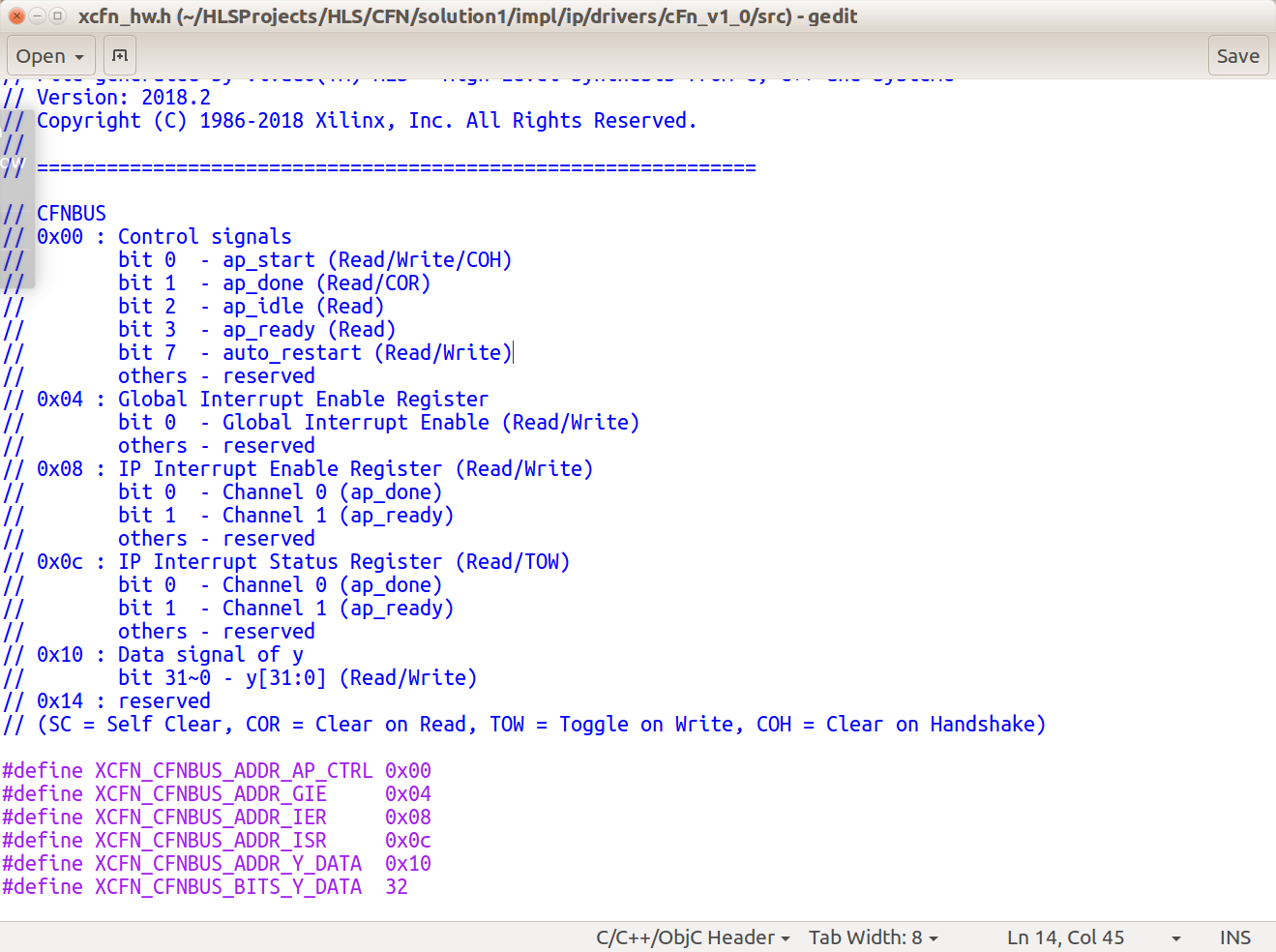
(by writing to /dev/xdma_user according to the base address + offset from above).
But for the life of me I couldn’t get it to work. The tell-tale sign that you’re having trouble with the control bus are errors in dmesg like
xdma:engine_status_dump: SG engine 0-C2H0-ST status: 0x00000001: BUSY
xdma:transfer_abort: abort transfer 0x00000000a4792062, desc 47, engine desc queued 0.
Using the ap_ctrl bundle to control the kernel IP amounts to just starting it by setting the appropriate pin to high:
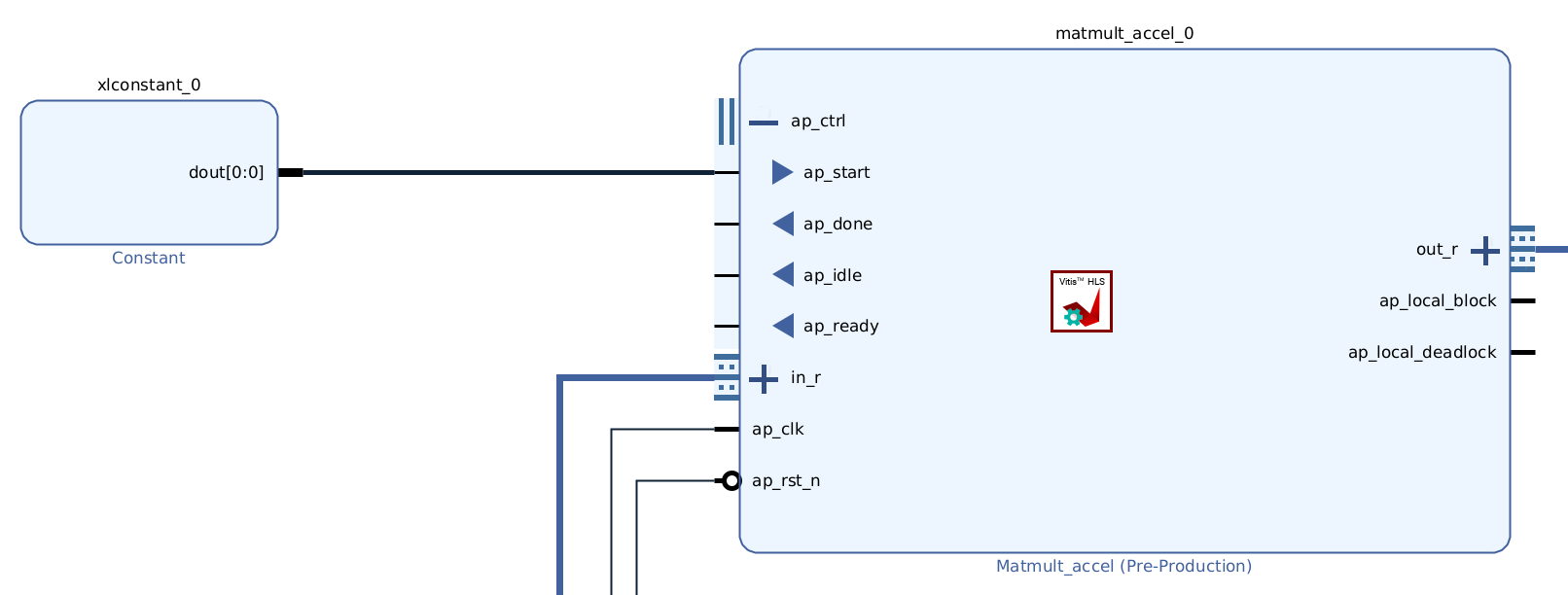
where xlconstant_0 actually has value 1.
One other thing to note is that the bus widths for the master and slave buses (S_AXIS_C2H_0, M_AXIS_H2C_0) are fixed (according to board specs?):
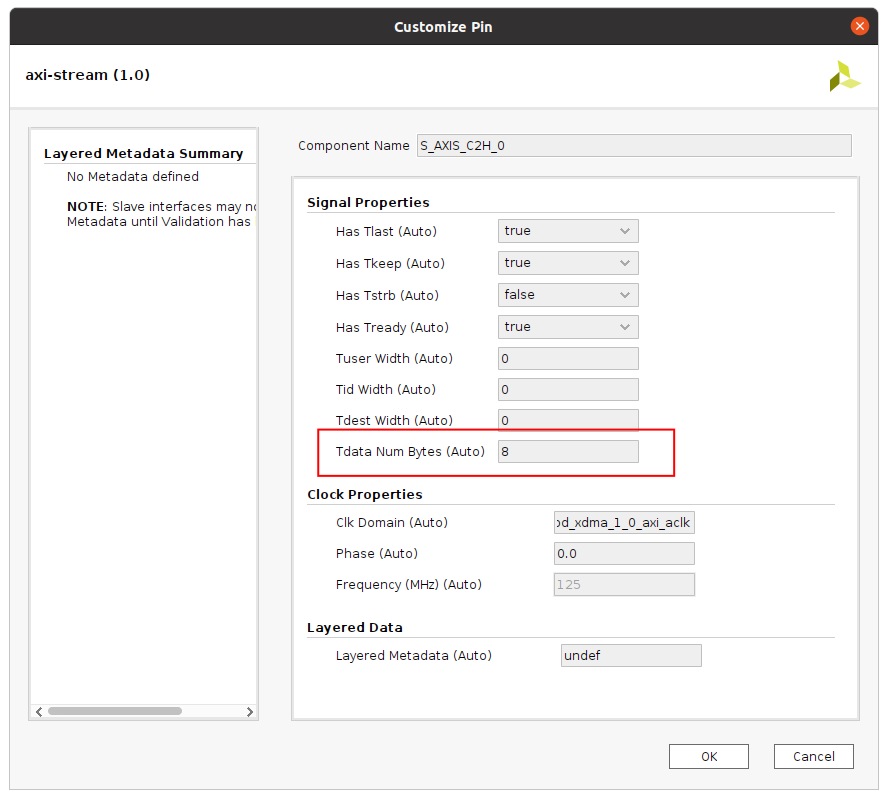
while the buses on the matmul block are determined by HLS/design:
#define DWIDTH 512
...
typedef ap_axiu<DWIDTH, WUSER, WID, WDEST> axis_t;
...
void matmult_accel(hls::stream<axis_t> &in, hls::stream<axis_t> &out)
reflected in the Vitis synthesis report
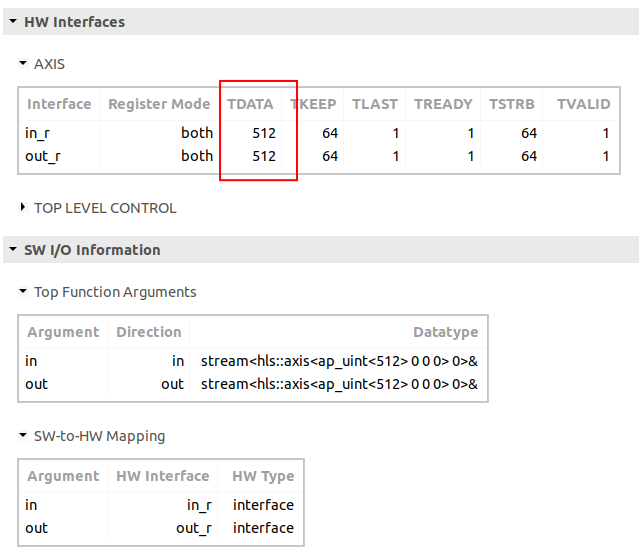
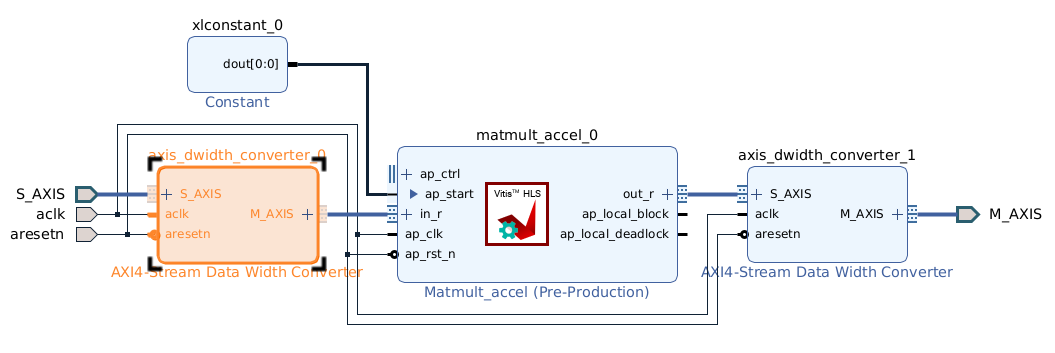
This means you need to use AXI4-Stream Data Width Converters for both master and slave ports on the kernel block:
configured appropriately:
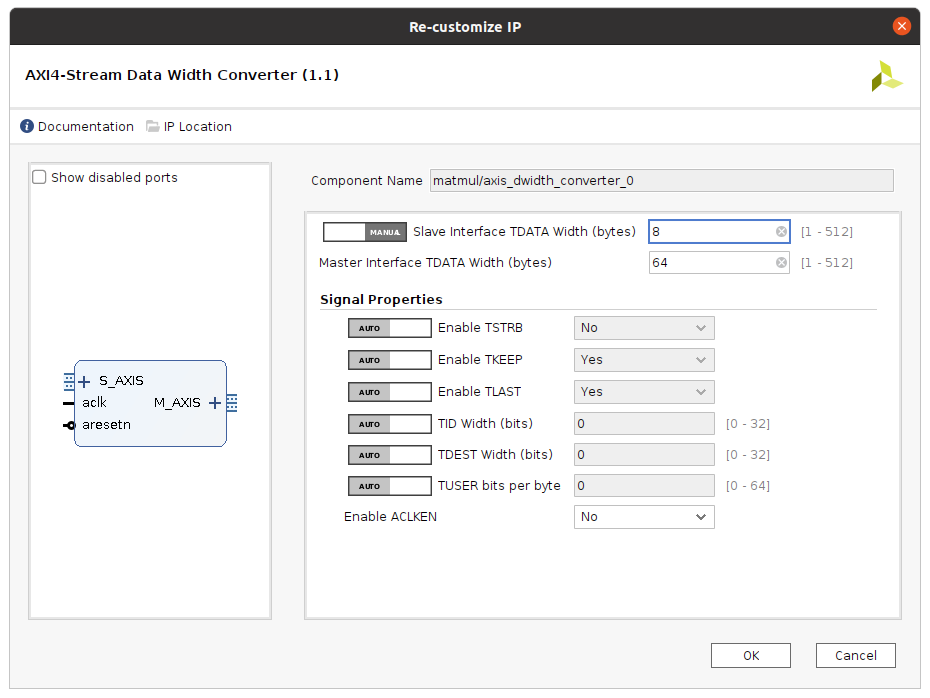
Note that Vitis report the bus width in terms of bits (512) while Vivado reports the bus width in terms of bytes (64); they’re the same (64 * 8 = 512).
Otherwise the block design looks like this (with kernel and stream-width converters grouped under matmul):
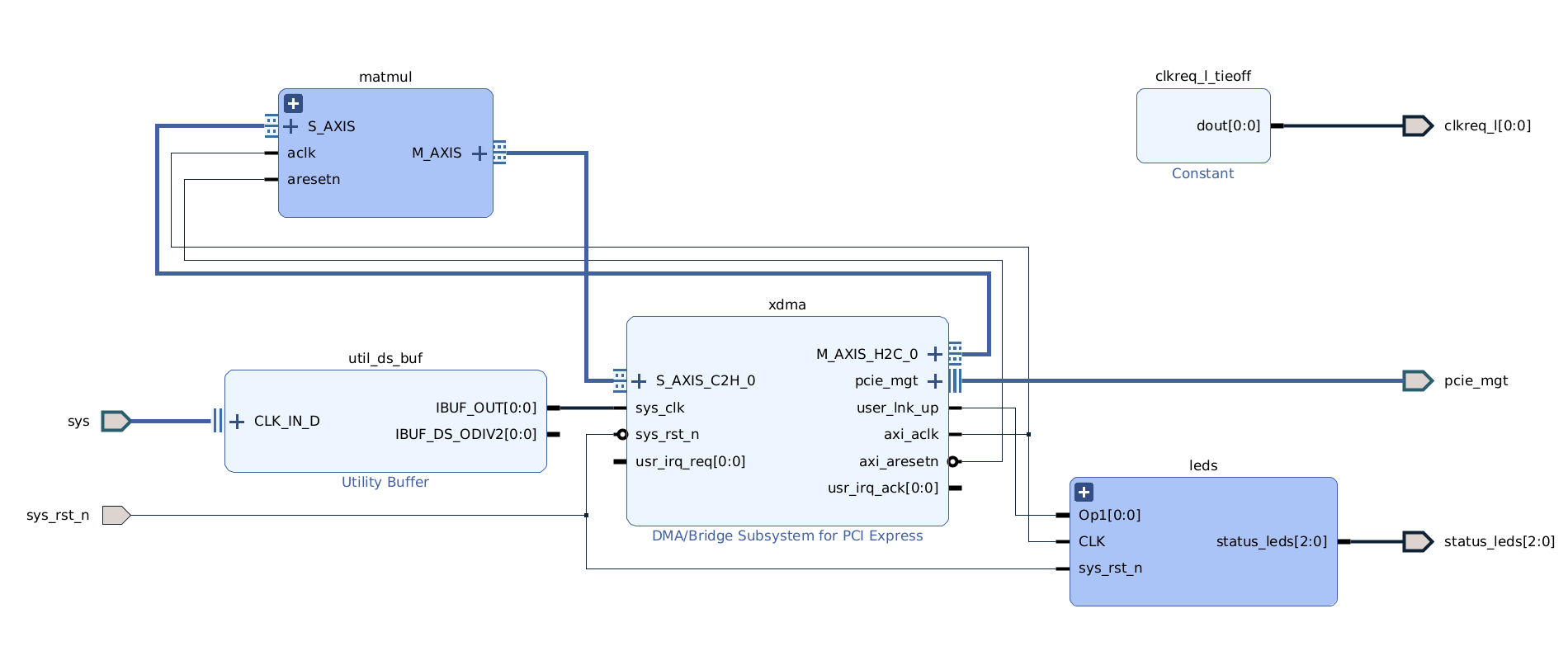
with XDMA configured as
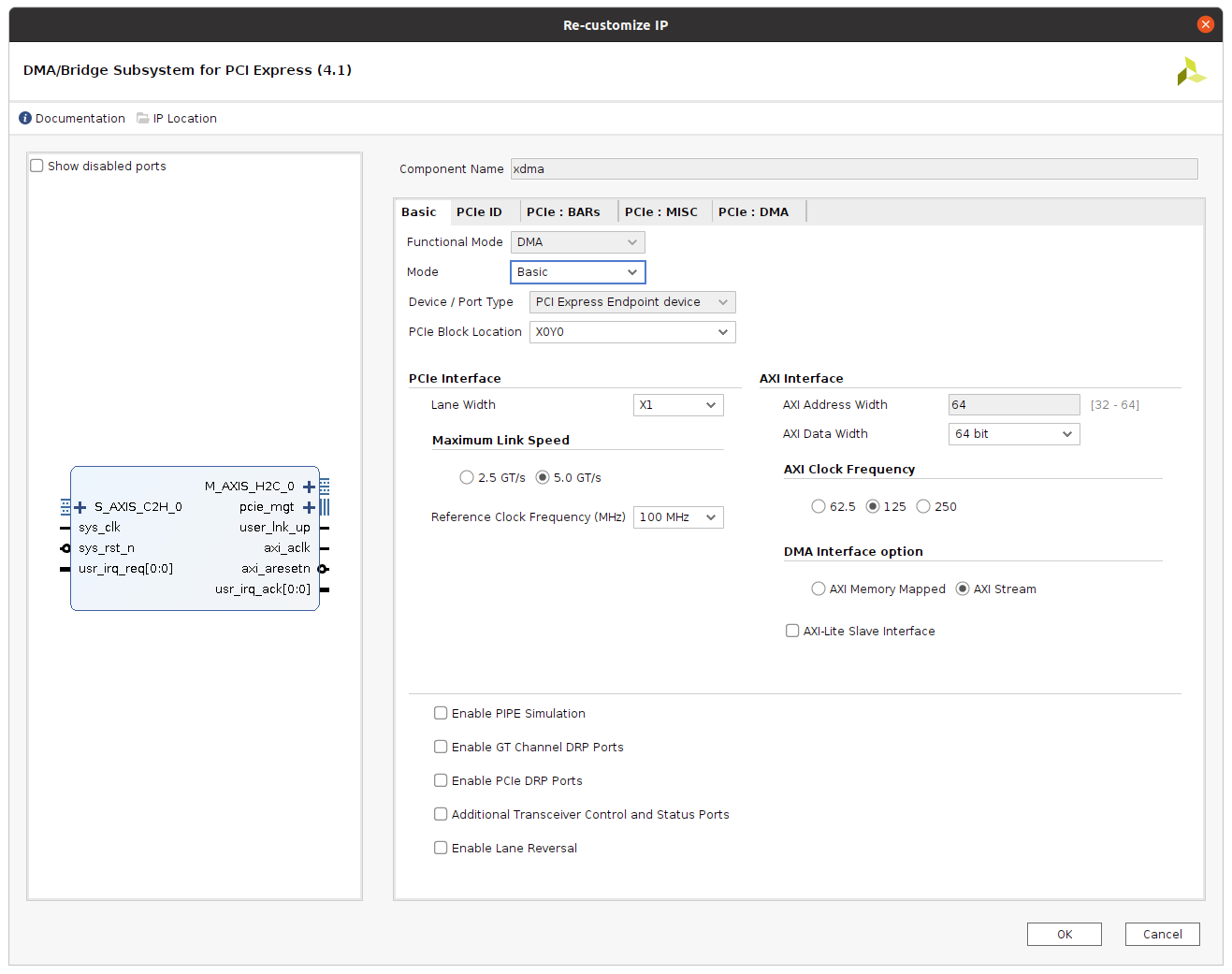
Debugging the Host
I had a lot of fun figuring out host side issues for this (that’s sarcasm…). There were two issues that I kept running into: dmesg logs like this
xdma:engine_status_dump: SG engine 0-C2H0-ST status: 0x00000001: BUSY
xdma:transfer_abort: abort transfer 0x00000000a4792062, desc 47, engine desc queued 0.
In particualr the BUSY warning (it can pop up around either C2H0 or H2C0). My understanding is that this has to do (basically) with the AXI blocks being stuck in a send or receive state (🤷). That issue was resolved by removing the s_axilite port on the kernel.
The next issue was much more intimidating; things like this started appearing as a pruned down the example code from ResearchLLC
[635799.492540] xdma:xdma_mod_init: Xilinx XDMA Reference Driver xdma v2017.1.47
[635799.492542] xdma:xdma_mod_init: desc_blen_max: 0xfffffff/268435455, sgdma_timeout: 10 sec.
[635799.492563] xdma:xdma_device_open: xdma device 0000:04:00.0, 0x00000000fd37877b.
[635799.492564] xdma:alloc_dev_instance: xdev = 0x000000007df08759
[635799.492565] xdma:xdev_list_add: dev 0000:04:00.0, xdev 0x000000007df08759, xdma idx 0.
[635799.492642] xdma:pci_check_extended_tag: 0x00000000fd37877b EXT_TAG disabled.
[635799.492643] xdma:pci_check_extended_tag: pdev 0x00000000fd37877b, xdev 0x000000007df08759, config bar UNKNOWN.
[635799.492650] xdma:request_regions: pci_request_regions()
[635799.492652] xdma:map_single_bar: BAR0: 1048576 bytes to be mapped.
[635799.492679] xdma:map_single_bar: BAR0 at 0xdf300000 mapped at 0x00000000a16149d0, length=1048576(/1048576)
[635799.492683] xdma:is_config_bar: BAR 0 is NOT the XDMA config BAR: 0xffffffff, 0xffffffff.
[635799.492683] xdma:map_single_bar: BAR2: 65536 bytes to be mapped.
[635799.492691] xdma:map_single_bar: BAR2 at 0xdf400000 mapped at 0x0000000095d37002, length=65536(/65536)
[635799.492694] xdma:is_config_bar: BAR 2 is NOT the XDMA config BAR: 0xffffffff, 0xffffffff.
[635799.492695] xdma:map_bars: Failed to detect XDMA config BAR
[635799.517276] xdma: probe of 0000:04:00.0 failed with error -22
This turned out to be due to a bug in Xilinx’s XDMA drivers. I didn’t figure this out but there’s a post and response on Xilinx’s forums that dicusses the issue; I reprint here for posterity’s sake (Xilinx’s forums have a tendency to lose posts just when you need them):
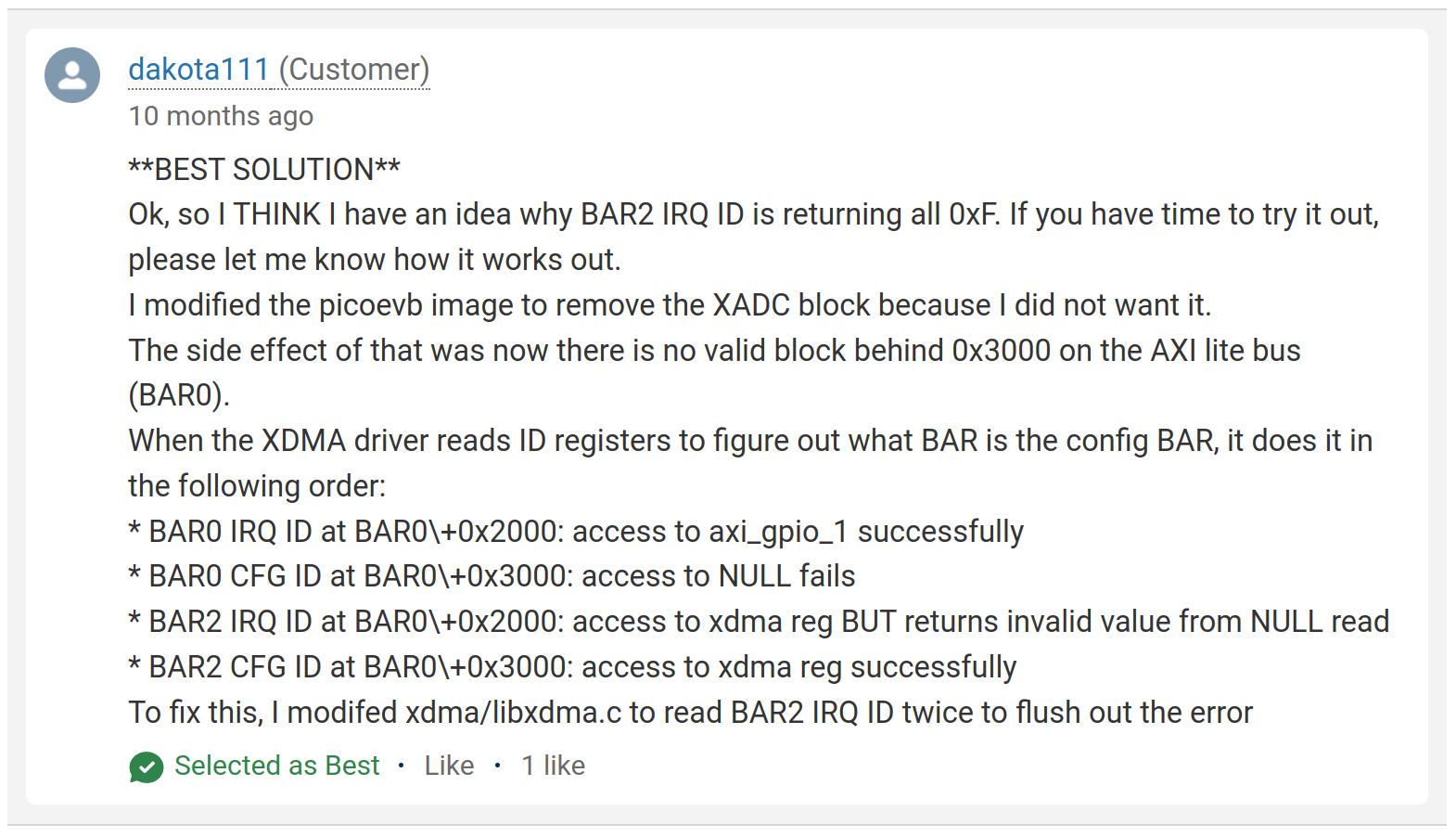
Implementing the fix involves patching xdma/libxdma.c (roughly) like this:
irq_id = read_register(&irq_regs->identifier);
+ if (idx == 2) {
+ irq_id = read_register(&irq_regs->identifier);
+ }
cfg_id = read_register(&cfg_regs->identifier);
This did infact enable the driver to recognize the config BAR but the results of the kernel (when read by the driver) were still wrong. Ultimately the most robust fix was ditching the s_axilite port on the kernel (though I’m sure that that’s the wrong choice for whatever reason).
In retrospect most of them came from not understanding exactly how control works for AXIS (see here).
End-to-End
Finally, sending data over PCIE to the kernel and then reading it back wasn’t so difficult but took some experimentation. In particular, you need to start to listen for a result before you send the input. One way to do this is to run a process (e.g., python script) that reads from /dev/xdma0_c2h_0 in one terminal and then run another process that writes to /dev/xdma0_h2c_0, i.e., something like:
# dma from device
import struct
import os
import numpy as np
xdma_axis_wr_data = os.open('/dev/xdma0_h2c_0',os.O_WRONLY)
SIZE = 8*8*2
data = [i for i in range(SIZE)]
data = struct.pack(f'<{SIZE}f', *data)
os.pwrite(xdma_axis_wr_data, data, 0)
and
import struct
import os
import numpy as np
xdma_axis_rd_data = os.open('/dev/xdma0_c2h_0', os.O_RDONLY)
SIZE = 64
data = os.pread(xdma_axis_rd_data, SIZE*4, 0)
data_unpack = np.array(struct.unpack(f'<{SIZE}f', data))
print(data_unpack.reshape(8,8))
Note that we’re sending two matrices (SIZE = 8*8*2) as inputs and then reading one matrix of 64 elements each comprised by 4 bytes (64*4).
This works fine but is tedious; the final script (here) uses asyncio:
async def to_device():
xdma_axis_wr_data = os.open("/dev/xdma0_h2c_0", os.O_WRONLY)
print(f"{MAT_A=}")
print(f"{MAT_B=}")
buffer = np.concatenate([MAT_A, MAT_B])
os.write(xdma_axis_wr_data, buffer.tobytes())
async def from_device():
xdma_axis_rd_data = os.open("/dev/xdma0_c2h_0", os.O_RDONLY)
buffer_size = MATRIX_DIM * MATRIX_DIM * DATA_BYTES
data = os.read(xdma_axis_rd_data, buffer_size)
output = np.frombuffer(data, dtype=DATA_TYPE).reshape(MATRIX_DIM, MATRIX_DIM)
print(f"{output=}")
assert np.allclose(MAT_C, output)
async def matmul():
# don't flip the order!
await to_device()
await from_device()
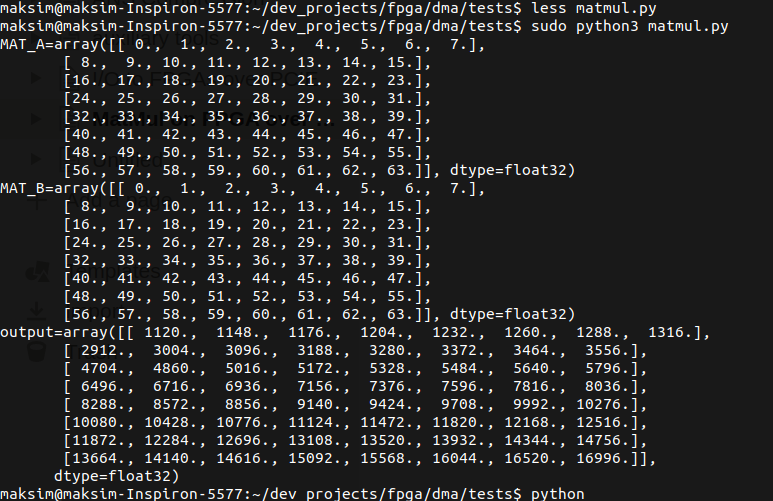
And the sweet sweet verification:
Next step is to get a whole NN on the board.
Useful links
- https://www.fpgadeveloper.com/2014/08/using-the-axi-dma-in-vivado.html/
- https://fpgaemu.readthedocs.io/en/latest/axi_pcie.html
- https://pp4fpgas.readthedocs.io/en/latest/axidma2.html
- https://www.linkedin.com/pulse/xilinx-dma-pcie-tutorial-part-1-roy-messinger/
- https://www.controlpaths.com/2021/10/11/fft-algorithm-using-an-fpga-and-xdma/